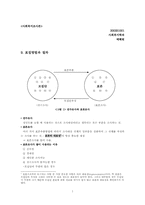
(1) 전망이론(prospect theory) 및 확률가중함수(probability)에 대하여 설명하고, 수업시간에 다룬 예시 이외에 전망이론과 확률가중함수로 설명할 수 있는 현상을 각각 한 가지씩 서술하라.
1) 전망이론
전망 이론은 사람들이 이익과 손실을 다르게 인지하고, 확률을 비선형적으로 평가한다는 것을 설명하
Introduction
What is EMR?
EMR(Electronic Medical Records) is a scanned digital version of a paper medical record. EMR System is a computer-based database system specific to one position or organization, and largely used to workers for diagnoses and treatment . It is a digital record that doctors keep on their own patients’ personal information, medical history, and diagnoses. The information
Purpose
The researcher must guarantee that every individual has an equal opportunity for selection and this can be achieved if the researcher utilizes randomization.
way
To select
some units which can represent whole, from a total set of units
The Types Of
Probability Samplings
Simple Random Sampling
Systematic Random Sampling
Stratified Random Sampling
Cluster And Multi-Stage
1. Topic
1.1. Topic
Analysis of various factors affecting the selling price of the car
1.2. Research purpose
Nowadays, there are many different models of cars and their prices range. So we want to know what
thefactors arewhich affect the selling price of the car and how much each variable explains the selling price.
1.3. Research process
To determine if there is a correlation between
False Memory ?
What’s False memory?
- the recollection of an event, or the details of an event, that did not occur
- effected by prompts and cues
- one of the memory failures
"Lost in the Mall"
Experiment done by Elizabeth Loftus and Jacqueline E. Pickrell
Purpose
to implant a false memory of getting lost in the mall when they were 5 years old.
Our Experiment
Hypo
I. 서론
표본추출은 분석대상 전체에서 선택된 일부가 표본(sample)이며 표본을 선택하는 과정을 표본추출(sampling)이라고 한다. 표본 대상으로 자료를 수집하는 경우에도 수집한 자료의 처리결과는 모집단을 대상으로 일반화(generalization)할 수 있어야 하여 전체대상의 특성을 대표할 수 있는지의 여부,
Ⅰ. 통계적 자료 분석
1.기본개념
1)빈도분포 (Frequency distribution)
(1) 개념
어떤 집단에서 측정치를 그 집단의 의미있는 특징을 밝히기 위해 수치들을 정리하게 된다. 이런 수치들의 정리는 여러 가지 통계적 처리를 간편하게 해주며, 연구보고서나 논문에서 원자료를 대신해서 매우 의미있는 역할을
error)
모집단 전체를 조사하는 것이 아니므로 표본의 크기를 어떤 규모로 하느냐에 따라서 표집오차를 가지게 되는데, 이 때 허용되는 수준의 표집오차를 확보할 수 있어야 한다.
(2) 무작위표집이 아닌 임의적인 표본추출을 할 경우, 연구자의 의도를 배제할 수 없어 당연히 모집단을 반영할 수 없어
Logistic Regression & Probit Regression by SPSS
I. Logistic regression
A. Extension of multiple regression but the dv is categorical
B. Value being predicted represents a probability, and it varies between 0 and 1
C. Possible to use categorical ivs (dummy coded, but won’t here)
D. Key concept: logit
1. natural logarithm (ln) of the odds
2.
3. Therefore, prob success + ? + + + +
E. SPS
Ⅰ 서론
21세기는 정보의 사회이다. 따라서 엄청난 양의 정보들이 넘쳐나고 있으며 앞으로 그 양은 기하급수적으로 많아질 것으로 예상된다. 특별히 자본주의의 강화 그리고 세계적으로 강력하게 대두되는 민주화 경향등에 의하여 모든 사람들의 행동양태, 관심 또는 흥미사항을 파악하기 위한 자료